
I. Transformer — Complete Learning Handbook
1. Architecture Overview (架构总览)
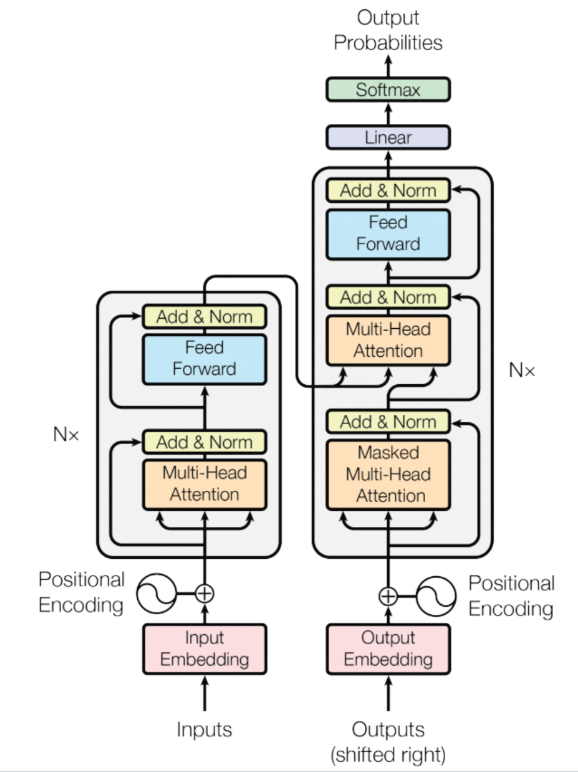
A standard Encoder-Decoder Transformer (编码器-解码器变换器) consists of:
Input Tokens ↓[Token Embedding + Positional Encoding] ↓┌─────────────────────────────────┐│ Encoder (编码器) × N layers ││ ┌──────────────────────────┐ ││ │ Multi-Head Self-Attention│ ││ │ Add & Norm │ ││ │ Feed-Forward Network │ ││ │ Add & Norm │ ││ └──────────────────────────┘ │└─────────────────────────────────┘ ↓ (encoder output = memory)┌─────────────────────────────────┐│ Decoder (解码器) × N layers ││ ┌──────────────────────────┐ ││ │ Masked Self-Attention │ ││ │ Add & Norm │ ││ │ Cross-Attention │ ││ │ Add & Norm │ ││ │ Feed-Forward Network │ ││ │ Add & Norm │ ││ └──────────────────────────┘ │└─────────────────────────────────┘ ↓Linear + Softmax → Output Probabilities2. Scaled Dot-Product Attention (缩放点积注意力)
1) The Formula
The core attention operation:
- Q (Query, 查询): What is each token looking for?
- K (Key, 键): How can this token be found by others?
- V (Value, 值): What does this token actually offer?
- (scaling factor, 缩放因子): Prevents softmax saturation when is large
2) Implementation
import torchimport torch.nn as nnimport torch.nn.functional as Fimport math
def scaled_dot_product_attention( Q: torch.Tensor, # (batch, heads, seq_q, d_k) K: torch.Tensor, # (batch, heads, seq_k, d_k) V: torch.Tensor, # (batch, heads, seq_k, d_v) mask: torch.Tensor = None,) -> tuple[torch.Tensor, torch.Tensor]: d_k = Q.size(-1)
# Step 1: Compute attention scores scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(d_k) # scores shape: (batch, heads, seq_q, seq_k)
# Step 2: Apply mask (set -inf so softmax → 0) if mask is not None: scores = scores.masked_fill(mask == 0, float('-inf'))
# Step 3: Softmax over key dimension attn_weights = F.softmax(scores, dim=-1) # (batch, heads, seq_q, seq_k)
# Step 4: Weighted sum of values output = torch.matmul(attn_weights, V) # (batch, heads, seq_q, d_v)
return output, attn_weights√d_k is critical. Without it, dot products grow large as d_k increases, pushing softmax into regions with extremely small gradients — causing the vanishing gradient problem (梯度消失) during training.3. Multi-Head Attention (多头注意力)
1) Motivation
A single attention head can only attend to one “subspace” at a time. Multi-Head Attention (多头注意力) runs attention heads in parallel, each learning to focus on different aspects (syntax, semantics, coreference, etc.), then concatenates and projects the results.
2) Implementation
class MultiHeadAttention(nn.Module): def __init__(self, d_model: int, num_heads: int, dropout: float = 0.1): super().__init__() assert d_model % num_heads == 0, "d_model must be divisible by num_heads"
self.d_model = d_model self.num_heads = num_heads self.d_k = d_model // num_heads # Dimension per head
# Linear projections for Q, K, V, and output self.W_q = nn.Linear(d_model, d_model, bias=False) self.W_k = nn.Linear(d_model, d_model, bias=False) self.W_v = nn.Linear(d_model, d_model, bias=False) self.W_o = nn.Linear(d_model, d_model, bias=False)
self.dropout = nn.Dropout(dropout)
def split_heads(self, x: torch.Tensor) -> torch.Tensor: """(batch, seq, d_model) → (batch, heads, seq, d_k)""" batch, seq, _ = x.size() x = x.view(batch, seq, self.num_heads, self.d_k) return x.transpose(1, 2) # (batch, heads, seq, d_k)
def forward( self, query: torch.Tensor, # (batch, seq_q, d_model) key: torch.Tensor, # (batch, seq_k, d_model) value: torch.Tensor, # (batch, seq_k, d_model) mask: torch.Tensor = None, ) -> torch.Tensor: # Project inputs to Q, K, V Q = self.split_heads(self.W_q(query)) # (batch, heads, seq_q, d_k) K = self.split_heads(self.W_k(key)) # (batch, heads, seq_k, d_k) V = self.split_heads(self.W_v(value)) # (batch, heads, seq_k, d_k)
# Scaled dot-product attention attn_output, _ = scaled_dot_product_attention(Q, K, V, mask) # attn_output: (batch, heads, seq_q, d_k)
# Concatenate heads batch, _, seq_q, _ = attn_output.size() attn_output = attn_output.transpose(1, 2).contiguous() attn_output = attn_output.view(batch, seq_q, self.d_model) # attn_output: (batch, seq_q, d_model)
# Final linear projection return self.W_o(attn_output)4. Position-wise Feed-Forward Network (逐位置前馈网络)
Applied independently to each position — acts as a two-layer MLP (多层感知机) with an inner expansion:
class FeedForward(nn.Module): def __init__(self, d_model: int, d_ff: int, dropout: float = 0.1): super().__init__() # Standard expansion: d_ff = 4 * d_model self.linear1 = nn.Linear(d_model, d_ff) self.linear2 = nn.Linear(d_ff, d_model) self.dropout = nn.Dropout(dropout)
def forward(self, x: torch.Tensor) -> torch.Tensor: # x: (batch, seq, d_model) x = self.linear1(x) # (batch, seq, d_ff) x = F.relu(x) # ReLU activation (or GELU in modern variants) x = self.dropout(x) x = self.linear2(x) # (batch, seq, d_model) return x5. Positional Encoding (位置编码)
Since Transformers have no recurrence, positional information must be injected explicitly. The original paper uses sinusoidal encoding (正弦编码):
class PositionalEncoding(nn.Module): def __init__(self, d_model: int, max_seq_len: int = 5000, dropout: float = 0.1): super().__init__() self.dropout = nn.Dropout(dropout)
# Build the positional encoding table once pe = torch.zeros(max_seq_len, d_model) # (max_len, d_model) position = torch.arange(0, max_seq_len).unsqueeze(1) # (max_len, 1) div_term = torch.exp( torch.arange(0, d_model, 2) * (-math.log(10000.0) / d_model) )
pe[:, 0::2] = torch.sin(position * div_term) # Even indices pe[:, 1::2] = torch.cos(position * div_term) # Odd indices pe = pe.unsqueeze(0) # (1, max_len, d_model)
# Register as buffer (not a parameter — not updated during training) self.register_buffer('pe', pe)
def forward(self, x: torch.Tensor) -> torch.Tensor: # x: (batch, seq, d_model) x = x + self.pe[:, :x.size(1)] # Add positional encoding return self.dropout(x)6. Add & Norm — Residual Connection + Layer Normalization
Each sub-layer is wrapped with a residual connection (残差连接) and Layer Normalization (层归一化):
class AddNorm(nn.Module): def __init__(self, d_model: int, dropout: float = 0.1): super().__init__() self.norm = nn.LayerNorm(d_model) self.dropout = nn.Dropout(dropout)
def forward(self, x: torch.Tensor, sublayer_output: torch.Tensor) -> torch.Tensor: # Pre-norm variant: norm(x) → sublayer → + x (used in modern GPT-style) # Post-norm variant (original paper): x + sublayer(x) → norm return self.norm(x + self.dropout(sublayer_output))7. Encoder Layer (编码器层)
class EncoderLayer(nn.Module): def __init__(self, d_model: int, num_heads: int, d_ff: int, dropout: float = 0.1): super().__init__() self.self_attn = MultiHeadAttention(d_model, num_heads, dropout) self.ff = FeedForward(d_model, d_ff, dropout) self.norm1 = nn.LayerNorm(d_model) self.norm2 = nn.LayerNorm(d_model) self.dropout = nn.Dropout(dropout)
def forward(self, x: torch.Tensor, src_mask: torch.Tensor = None) -> torch.Tensor: # Self-attention + residual + norm attn_out = self.self_attn(x, x, x, src_mask) x = self.norm1(x + self.dropout(attn_out))
# Feed-forward + residual + norm ff_out = self.ff(x) x = self.norm2(x + self.dropout(ff_out))
return x
class Encoder(nn.Module): def __init__(self, num_layers: int, d_model: int, num_heads: int, d_ff: int, dropout: float): super().__init__() self.layers = nn.ModuleList([ EncoderLayer(d_model, num_heads, d_ff, dropout) for _ in range(num_layers) ]) self.norm = nn.LayerNorm(d_model)
def forward(self, x: torch.Tensor, src_mask: torch.Tensor = None) -> torch.Tensor: for layer in self.layers: x = layer(x, src_mask) return self.norm(x)8. Decoder Layer (解码器层)
The decoder has three sub-layers: masked self-attention, cross-attention over encoder output, and feed-forward.
class DecoderLayer(nn.Module): def __init__(self, d_model: int, num_heads: int, d_ff: int, dropout: float = 0.1): super().__init__() self.self_attn = MultiHeadAttention(d_model, num_heads, dropout) # Masked self.cross_attn = MultiHeadAttention(d_model, num_heads, dropout) # Cross self.ff = FeedForward(d_model, d_ff, dropout) self.norm1 = nn.LayerNorm(d_model) self.norm2 = nn.LayerNorm(d_model) self.norm3 = nn.LayerNorm(d_model) self.dropout = nn.Dropout(dropout)
def forward( self, x: torch.Tensor, # Decoder input (batch, tgt_seq, d_model) memory: torch.Tensor, # Encoder output (batch, src_seq, d_model) tgt_mask: torch.Tensor = None, # Causal mask for decoder self-attention src_mask: torch.Tensor = None, # Padding mask for cross-attention ) -> torch.Tensor: # 1. Masked self-attention (prevents attending to future tokens) attn1 = self.self_attn(x, x, x, tgt_mask) x = self.norm1(x + self.dropout(attn1))
# 2. Cross-attention over encoder memory attn2 = self.cross_attn(x, memory, memory, src_mask) x = self.norm2(x + self.dropout(attn2))
# 3. Feed-forward ff_out = self.ff(x) x = self.norm3(x + self.dropout(ff_out))
return x
class Decoder(nn.Module): def __init__(self, num_layers: int, d_model: int, num_heads: int, d_ff: int, dropout: float): super().__init__() self.layers = nn.ModuleList([ DecoderLayer(d_model, num_heads, d_ff, dropout) for _ in range(num_layers) ]) self.norm = nn.LayerNorm(d_model)
def forward(self, x, memory, tgt_mask=None, src_mask=None): for layer in self.layers: x = layer(x, memory, tgt_mask, src_mask) return self.norm(x)9. Masks (掩码)
1) Padding Mask (填充掩码)
Prevents attention over <PAD> tokens:
def make_pad_mask(seq: torch.Tensor, pad_idx: int = 0) -> torch.Tensor: """ seq: (batch, seq_len) — integer token IDs Returns: (batch, 1, 1, seq_len) — True where NOT padding """ return (seq != pad_idx).unsqueeze(1).unsqueeze(2)2) Causal Mask / Look-ahead Mask (因果掩码)
Prevents decoder positions from attending to future positions:
def make_causal_mask(seq_len: int, device: torch.device) -> torch.Tensor: """ Returns lower-triangular mask of shape (1, 1, seq_len, seq_len) Position i can attend to positions 0..i only. """ mask = torch.tril(torch.ones(seq_len, seq_len, device=device)) return mask.unsqueeze(0).unsqueeze(0) # (1, 1, seq_len, seq_len)10. Complete Transformer Model (完整模型)
class Transformer(nn.Module): def __init__( self, src_vocab_size: int, tgt_vocab_size: int, d_model: int = 512, num_heads: int = 8, num_layers: int = 6, d_ff: int = 2048, max_seq_len: int = 512, dropout: float = 0.1, pad_idx: int = 0, ): super().__init__() self.pad_idx = pad_idx self.d_model = d_model
# Embeddings self.src_embedding = nn.Embedding(src_vocab_size, d_model, padding_idx=pad_idx) self.tgt_embedding = nn.Embedding(tgt_vocab_size, d_model, padding_idx=pad_idx) self.pos_encoding = PositionalEncoding(d_model, max_seq_len, dropout)
# Encoder & Decoder self.encoder = Encoder(num_layers, d_model, num_heads, d_ff, dropout) self.decoder = Decoder(num_layers, d_model, num_heads, d_ff, dropout)
# Output projection self.fc_out = nn.Linear(d_model, tgt_vocab_size)
# Weight initialization self._init_weights()
def _init_weights(self): for p in self.parameters(): if p.dim() > 1: nn.init.xavier_uniform_(p)
def encode(self, src: torch.Tensor, src_mask: torch.Tensor = None) -> torch.Tensor: x = self.pos_encoding(self.src_embedding(src) * math.sqrt(self.d_model)) return self.encoder(x, src_mask)
def decode( self, tgt: torch.Tensor, memory: torch.Tensor, tgt_mask: torch.Tensor = None, src_mask: torch.Tensor = None, ) -> torch.Tensor: x = self.pos_encoding(self.tgt_embedding(tgt) * math.sqrt(self.d_model)) return self.decoder(x, memory, tgt_mask, src_mask)
def forward( self, src: torch.Tensor, # (batch, src_len) tgt: torch.Tensor, # (batch, tgt_len) ) -> torch.Tensor: # Build masks src_mask = make_pad_mask(src, self.pad_idx) tgt_pad_mask = make_pad_mask(tgt, self.pad_idx) tgt_causal = make_causal_mask(tgt.size(1), tgt.device) tgt_mask = tgt_pad_mask & tgt_causal # Combine both
# Forward pass memory = self.encode(src, src_mask) output = self.decode(tgt, memory, tgt_mask, src_mask)
# Project to vocabulary return self.fc_out(output) # (batch, tgt_len, tgt_vocab_size)11. Training (训练)
1) Hyperparameters & Setup
import torchimport torch.optim as optimfrom torch.utils.data import DataLoader, Dataset
# ---- Hyperparameters ----SRC_VOCAB = 8000TGT_VOCAB = 8000D_MODEL = 256NUM_HEADS = 8NUM_LAYERS = 4D_FF = 1024MAX_LEN = 128DROPOUT = 0.1PAD_IDX = 0BOS_IDX = 1EOS_IDX = 2BATCH_SIZE = 32EPOCHS = 20LR = 1e-4DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# ---- Model ----model = Transformer( src_vocab_size=SRC_VOCAB, tgt_vocab_size=TGT_VOCAB, d_model=D_MODEL, num_heads=NUM_HEADS, num_layers=NUM_LAYERS, d_ff=D_FF, max_seq_len=MAX_LEN, dropout=DROPOUT, pad_idx=PAD_IDX,).to(DEVICE)
print(f"Parameters: {sum(p.numel() for p in model.parameters()):,}")2) Learning Rate Scheduler — Warmup (学习率预热)
The original paper uses a custom schedule:
class WarmupScheduler: def __init__(self, optimizer, d_model: int, warmup_steps: int = 4000): self.optimizer = optimizer self.d_model = d_model self.warmup_steps = warmup_steps self.step_num = 0
def step(self): self.step_num += 1 lr = self.d_model ** (-0.5) * min( self.step_num ** (-0.5), self.step_num * self.warmup_steps ** (-1.5) ) for param_group in self.optimizer.param_groups: param_group['lr'] = lr
optimizer = optim.Adam(model.parameters(), lr=0, betas=(0.9, 0.98), eps=1e-9)scheduler = WarmupScheduler(optimizer, d_model=D_MODEL, warmup_steps=4000)criterion = nn.CrossEntropyLoss(ignore_index=PAD_IDX, label_smoothing=0.1)label_smoothing=0.1 distributes 10% of the probability mass uniformly across all tokens instead of concentrating it on the correct token. This regularizes the model and prevents overconfidence.3) Dummy Dataset for Demonstration
class Seq2SeqDataset(Dataset): """ Minimal demo dataset — replace with real tokenized data. Each sample is (src_ids, tgt_ids). """ def __init__(self, size=1000, src_vocab=8000, tgt_vocab=8000, src_len=20, tgt_len=22): self.data = [ ( torch.randint(3, src_vocab, (src_len,)), torch.randint(3, tgt_vocab, (tgt_len,)), ) for _ in range(size) ]
def __len__(self): return len(self.data)
def __getitem__(self, idx): return self.data[idx]
def collate_fn(batch): """Pad sequences in a batch to the same length.""" src_batch, tgt_batch = zip(*batch) src_padded = torch.nn.utils.rnn.pad_sequence(src_batch, batch_first=True, padding_value=PAD_IDX) tgt_padded = torch.nn.utils.rnn.pad_sequence(tgt_batch, batch_first=True, padding_value=PAD_IDX) return src_padded, tgt_padded
train_dataset = Seq2SeqDataset(size=2000)train_loader = DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True, collate_fn=collate_fn)4) Training Loop (训练循环)
def train_epoch(model, loader, optimizer, scheduler, criterion, device): model.train() total_loss = 0.0 total_tokens = 0
for batch_idx, (src, tgt) in enumerate(loader): src = src.to(device) # (batch, src_len) tgt = tgt.to(device) # (batch, tgt_len)
# Teacher forcing (教师强制): # Input to decoder: tgt[:, :-1] (all but last token) # Target from model: tgt[:, 1:] (all but first token = BOS) tgt_input = tgt[:, :-1] tgt_target = tgt[:, 1:]
# Forward pass logits = model(src, tgt_input) # logits: (batch, tgt_len-1, tgt_vocab_size)
# Reshape for cross-entropy logits_flat = logits.reshape(-1, logits.size(-1)) # (batch*(tgt-1), vocab) targets_flat = tgt_target.reshape(-1) # (batch*(tgt-1),)
loss = criterion(logits_flat, targets_flat)
# Backward pass optimizer.zero_grad() loss.backward() torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0) # Gradient clipping optimizer.step() scheduler.step()
# Track metrics non_pad = (tgt_target != PAD_IDX).sum().item() total_loss += loss.item() * non_pad total_tokens += non_pad
if batch_idx % 50 == 0: print(f" Batch {batch_idx}/{len(loader)} " f"Loss: {loss.item():.4f} " f"LR: {optimizer.param_groups[0]['lr']:.6f}")
return total_loss / total_tokens
def evaluate(model, loader, criterion, device): model.eval() total_loss = 0.0 total_tokens = 0
with torch.no_grad(): for src, tgt in loader: src = src.to(device) tgt = tgt.to(device) tgt_input = tgt[:, :-1] tgt_target = tgt[:, 1:]
logits = model(src, tgt_input) loss = criterion(logits.reshape(-1, logits.size(-1)), tgt_target.reshape(-1))
non_pad = (tgt_target != PAD_IDX).sum().item() total_loss += loss.item() * non_pad total_tokens += non_pad
return total_loss / total_tokens
# ---- Main Training Loop ----best_val_loss = float('inf')
for epoch in range(1, EPOCHS + 1): train_loss = train_epoch(model, train_loader, optimizer, scheduler, criterion, DEVICE) # val_loss = evaluate(model, val_loader, criterion, DEVICE)
print(f"\nEpoch {epoch}/{EPOCHS} Train Loss: {train_loss:.4f} " f"Perplexity: {math.exp(train_loss):.2f}")
# Save best checkpoint torch.save({ 'epoch': epoch, 'model_state_dict': model.state_dict(), 'optimizer_state_dict': optimizer.state_dict(), 'loss': train_loss, }, 'transformer_best.pt')12. Inference — Greedy Decoding (贪婪解码)
The simplest decoding strategy: at each step, pick the token with the highest probability.
def greedy_decode( model: Transformer, src: torch.Tensor, # (1, src_len) — single example max_len: int = 50, bos_idx: int = BOS_IDX, eos_idx: int = EOS_IDX, device: torch.device = DEVICE,) -> list[int]: model.eval() src = src.to(device)
with torch.no_grad(): # Step 1: Encode source sequence once src_mask = make_pad_mask(src, PAD_IDX) memory = model.encode(src, src_mask) # (1, src_len, d_model)
# Step 2: Initialize decoder input with BOS token tgt = torch.tensor([[bos_idx]], device=device) # (1, 1) output_tokens = []
for _ in range(max_len): # Build causal mask for current target length tgt_mask = make_causal_mask(tgt.size(1), device)
# Decode one step dec_out = model.decode(tgt, memory, tgt_mask, src_mask) # dec_out: (1, tgt_len, d_model)
# Project and take argmax of last position logits = model.fc_out(dec_out[:, -1, :]) # (1, vocab) next_token = logits.argmax(dim=-1).item()
output_tokens.append(next_token)
if next_token == eos_idx: break
# Append predicted token and continue tgt = torch.cat([tgt, torch.tensor([[next_token]], device=device)], dim=1)
return output_tokens
# Example usagesrc_example = torch.randint(3, SRC_VOCAB, (1, 15))predicted = greedy_decode(model, src_example, max_len=50)print("Predicted token IDs:", predicted)13. Inference — Beam Search (束搜索)
Maintains the top-k candidate sequences at each step — much better output quality than greedy.
from dataclasses import dataclass, field
@dataclass(order=True)class BeamHypothesis: score: float tokens: list[int] = field(compare=False)
def beam_search_decode( model: Transformer, src: torch.Tensor, beam_size: int = 4, max_len: int = 50, bos_idx: int = BOS_IDX, eos_idx: int = EOS_IDX, device: torch.device = DEVICE, length_penalty: float = 0.6,) -> list[int]: model.eval() src = src.to(device)
with torch.no_grad(): src_mask = make_pad_mask(src, PAD_IDX) memory = model.encode(src, src_mask)
# Initialize beam with BOS token beams = [BeamHypothesis(score=0.0, tokens=[bos_idx])] completed = []
for step in range(max_len): all_candidates = []
for beam in beams: if beam.tokens[-1] == eos_idx: completed.append(beam) continue
tgt = torch.tensor([beam.tokens], device=device) tgt_mask = make_causal_mask(tgt.size(1), device)
dec_out = model.decode(tgt, memory, tgt_mask, src_mask) logits = model.fc_out(dec_out[:, -1, :]) # (1, vocab) log_probs = F.log_softmax(logits, dim=-1).squeeze(0) # (vocab,)
# Expand top-k tokens topk_log_probs, topk_ids = log_probs.topk(beam_size)
for log_prob, token_id in zip(topk_log_probs.tolist(), topk_ids.tolist()): new_score = beam.score + log_prob new_tokens = beam.tokens + [token_id] all_candidates.append( BeamHypothesis(score=new_score, tokens=new_tokens) )
if not all_candidates: break
# Keep top beam_size candidates all_candidates.sort(key=lambda h: h.score / (len(h.tokens) ** length_penalty), reverse=True) beams = all_candidates[:beam_size]
# Return best completed hypothesis (or best incomplete beam) all_hyps = completed + beams best = max(all_hyps, key=lambda h: h.score / (len(h.tokens) ** length_penalty)) return best.tokens[1:] # Strip BOS
predicted_beam = beam_search_decode(model, src_example, beam_size=4)print("Beam search tokens:", predicted_beam)14. Saving & Loading Checkpoints (保存与加载)
# ---- Save ----torch.save({ 'model_state_dict' : model.state_dict(), 'optimizer_state_dict': optimizer.state_dict(), 'epoch' : epoch, 'loss' : train_loss, 'config': { 'src_vocab': SRC_VOCAB, 'tgt_vocab': TGT_VOCAB, 'd_model': D_MODEL, 'num_heads': NUM_HEADS, 'num_layers': NUM_LAYERS, 'd_ff': D_FF, }}, 'transformer_checkpoint.pt')
# ---- Load ----checkpoint = torch.load('transformer_checkpoint.pt', map_location=DEVICE)cfg = checkpoint['config']
model = Transformer( src_vocab_size=cfg['src_vocab'], tgt_vocab_size=cfg['tgt_vocab'], d_model=cfg['d_model'], num_heads=cfg['num_heads'], num_layers=cfg['num_layers'], d_ff=cfg['d_ff'],).to(DEVICE)
model.load_state_dict(checkpoint['model_state_dict'])optimizer.load_state_dict(checkpoint['optimizer_state_dict'])model.eval()print(f"Loaded checkpoint from epoch {checkpoint['epoch']}")15. Key Design Decisions & Modern Variants (关键设计决策与现代变体)
| Component | Original Paper | Modern Practice |
|---|---|---|
| Positional Encoding | Sinusoidal (fixed) | Learned embeddings (BERT) / RoPE (LLaMA) |
| Normalization | Post-LN (后归一化) | Pre-LN (前归一化) — more stable |
| Activation | ReLU | GELU / SwiGLU (GPT, LLaMA) |
| Attention | Full self-attention | GQA / MQA (grouped/multi-query) — faster inference |
| Vocab size | ~37,000 | 32k–128k+ with BPE/SentencePiece |
| Weight tying | None | Tie input & output embeddings (GPT-2) |
| KV Cache | None | KV Cache (KV 缓存) for autoregressive inference |
| Context length | 512 | 4k–128k+ with sliding window or ALiBi |
A Transformer is a stack of Multi-Head Attention (多头注意力) + Feed-Forward (前馈网络) blocks tied together by Residual Connections (残差连接) + LayerNorm (层归一化) — master
scaled_dot_product_attention, understand causal masking, use warmup scheduling, and switch from greedy to beam search for better output quality.