741 words
4 minutes
Prefill-Decode Disaggregation

I. Prefill-Decode Disaggregation (PD 分离)
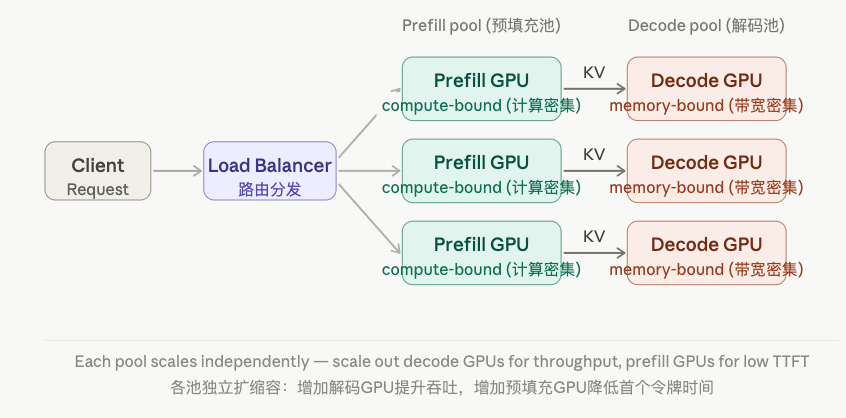
1. Motivation (动机)
In standard LLM serving, prefill and decode run on the same GPU and interfere with each other:
- Prefill is compute-bound (计算密集型): processes hundreds of tokens in parallel, saturates CUDA cores, one long iteration.
- Decode is memory-bandwidth-bound (内存带宽密集型): reads the full KV cache per step for just 1 new token, starved of compute.
Running them together causes prefill-decode interference (干扰):
- A large prefill blocks decode iterations → spikes in Inter-Token Latency (ITL, 令牌间延迟).
- Decode’s need for low batch size conflicts with prefill’s need for large batches.
PD disaggregation puts them on separate GPU pools so each can be tuned independently.
2. Architecture (架构)
1) Two Pools (两个资源池)
| Pool | Role | Bottleneck | Optimal hardware |
|---|---|---|---|
| Prefill pool (预填充池) | Process prompt tokens, build KV cache | Compute (FLOPs) | High-FLOP GPUs (e.g. H100 SXM) |
| Decode pool (解码池) | Autoregressive token generation | Memory bandwidth | High-bandwidth GPUs or more GPUs |
2) KV Cache Transfer (KV缓存传输)
After prefill completes, the KV cache must be migrated from the prefill GPU to the decode GPU. This is the central engineering challenge of PD disaggregation.
Where is the prompt length (提示长度). A 4096-token prompt on a 70B model generates ~8 GB of KV cache — transfer latency directly adds to TTFT (首个令牌时间).
Transfer methods (传输方式):
- NVLink — within a node, ~600 GB/s, negligible latency.
- RDMA over InfiniBand — across nodes, ~200–400 GB/s.
- TCP/IP — fallback, much slower, not recommended.
3. Runnable Example (可运行示例)
# Simulates PD-disaggregated scheduling with KV transfer cost.# No external dependencies required.
import timeimport threadingfrom queue import Queue
PREFILL_TIME_PER_TOKEN = 0.0005 # seconds per token (compute-bound)DECODE_TIME_PER_TOKEN = 0.020 # seconds per token (memory-bound)KV_TRANSFER_GBPS = 200 # simulated NVLink bandwidth (GB/s)BYTES_PER_KV_TOKEN = 2 * 80 * 8192 # 2 (K+V) × 80 layers × 8192 bytes
class Request: def __init__(self, req_id: str, prompt_len: int, max_new_tokens: int): self.req_id = req_id self.prompt_len = prompt_len self.max_new_tokens = max_new_tokens
def prefill_worker(req: Request, kv_queue: Queue): """Prefill pool: process prompt, produce KV cache.""" t0 = time.time() time.sleep(req.prompt_len * PREFILL_TIME_PER_TOKEN) # simulate compute prefill_ms = (time.time() - t0) * 1000
# Simulate KV cache transfer kv_bytes = BYTES_PER_KV_TOKEN * req.prompt_len transfer_s = kv_bytes / (KV_TRANSFER_GBPS * 1e9) time.sleep(transfer_s) transfer_ms = transfer_s * 1000
print(f"[Prefill→Transfer] {req.req_id}: " f"prefill={prefill_ms:.1f}ms transfer={transfer_ms:.1f}ms " f"KV={kv_bytes/1e6:.1f}MB") kv_queue.put(req) # hand off to decode pool
def decode_worker(kv_queue: Queue): """Decode pool: consume KV cache, generate tokens.""" while True: req = kv_queue.get() if req is None: break t0 = time.time() time.sleep(req.max_new_tokens * DECODE_TIME_PER_TOKEN) decode_ms = (time.time() - t0) * 1000 ttft = (req.prompt_len * PREFILL_TIME_PER_TOKEN + BYTES_PER_KV_TOKEN * req.prompt_len / (KV_TRANSFER_GBPS * 1e9) + DECODE_TIME_PER_TOKEN) * 1000 print(f"[Decode Done] {req.req_id}: " f"decode={decode_ms:.1f}ms est.TTFT={ttft:.1f}ms") kv_queue.task_done()
if __name__ == "__main__": requests = [ Request("R1", prompt_len=512, max_new_tokens=50), Request("R2", prompt_len=2048, max_new_tokens=20), Request("R3", prompt_len=256, max_new_tokens=100), ]
kv_queue: Queue = Queue()
# Start decode pool (always listening) decoder = threading.Thread(target=decode_worker, args=(kv_queue,), daemon=True) decoder.start()
# Prefill pool: process all requests (could be parallel in real systems) threads = [threading.Thread(target=prefill_worker, args=(r, kv_queue)) for r in requests] for t in threads: t.start() for t in threads: t.join()
kv_queue.join() kv_queue.put(None) # signal decoder to exit4. Benefits and Trade-offs (优缺点)
| Aspect | Coupled (耦合) | Disaggregated (分离) |
|---|---|---|
| TTFT | Higher (prefill blocks decode) | Lower (dedicated prefill GPUs) |
| ITL | Spikey under long prompts | Stable (no prefill interference) |
| Independent scaling (独立扩缩容) | No | Yes — scale each pool by workload |
| KV transfer overhead | None | Adds latency on long prompts |
| Hardware cost | Lower | Higher (more GPUs) |
5. Key Formula — Transfer Latency (传输延迟)
For a LLaMA-3 70B with a 4096-token prompt over 200 GB/s RDMA:
This 40 ms is added directly to TTFT — the central cost of PD disaggregation.
6. Related Concepts (相关概念)
- Chunked Prefill (分块预填充) — an alternative to PD disaggregation that interleaves prefill and decode on the same GPU; lower cost but less isolation.
- Continuous Batching (连续批处理) — iteration-level scheduling; used within each pool in PD disaggregation.
- KV Cache Migration (KV缓存迁移) — the core engineering problem: moving large tensors across GPUs with minimal TTFT penalty.
- Mooncake / Splitwise / DistServe — research systems that implement PD disaggregation at production scale.
Prefill-Decode Disaggregation
https://lxy-alexander.github.io/blog/posts/llm/prefill-decode-disaggregation/