
I. Chunked Prefill (分块预填充)
1. Background
In Large Language Model (大语言模型) inference, processing a request has two phases:
- Prefill (预填充): The model processes all input prompt tokens in parallel, building the KV Cache (键值缓存). This is compute-bound (计算密集型).
- Decode (解码): The model generates one output token per iteration, autoregressively. This is memory-bandwidth-bound (内存带宽密集型).
Without chunked prefill, a single long-prompt prefill request can monopolize the GPU for many milliseconds, blocking decode iterations for other requests and inflating the Time to First Token (TTFT, 首个令牌时间) and Inter-Token Latency (ITL, 令牌间延迟) for concurrent users.
It improves GPU utilization, reduces latency, increases throughput, and ensures fair scheduling across requests.
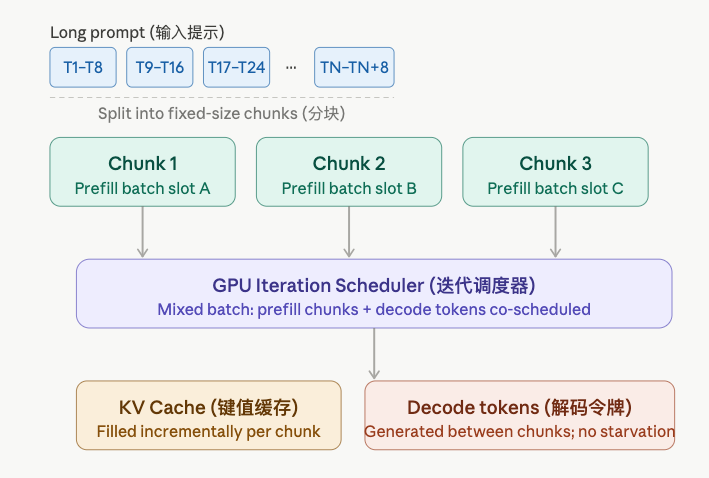
2. What Is Chunked Prefill?
Chunked Prefill splits a long prefill sequence into fixed-size pieces called chunks, In the same GPU iteration, it processes: - decode tokens from some requests - prefill chunks from other requests.
Key Insight: Instead of “finish all prefill, then decode,” we interleave them so the GPU is always doing useful, mixed work.
1) Core Idea
Each iteration processes:
- A chunk of
Ctokens from one (or more) prefilling requests. - All current decode tokens from already-started requests.
2) Chunk Size (块大小)
chunk_size (e.g., 512 or 1024 tokens) is a tunable hyperparameter (超参数):
| Chunk size | Effect |
|---|---|
| Smaller | Lower TTFT jitter, better fairness, more scheduling overhead |
| Larger | Higher GPU utilization, less overhead, longer decode stalls |
3. Algorithm
1) Scheduler Logic (调度器逻辑)
# Pseudocode — runs once per GPU iterationdef schedule_iteration(prefill_queue, decode_queue, chunk_size): batch = []
# Step 1: Add decode tokens for all running requests for req in decode_queue: batch.append(DecodeToken(req)) # 1 token per running request
# Step 2: Fill remaining compute budget with one prefill chunk if prefill_queue: req = prefill_queue[0] start = req.processed_tokens # where we left off end = min(start + chunk_size, len(req.prompt)) batch.append(PrefillChunk(req, start, end)) req.processed_tokens = end if req.processed_tokens == len(req.prompt): prefill_queue.pop(0) # prefill done → move to decode_queue
return batch2) KV Cache Construction (键值缓存构建)
Because prefill is chunked, the KV cache is filled incrementally:
Each chunk appends its computed key-value pairs to the existing cache. This is correct because attention (注意力机制) only requires the cache to be causally complete — past tokens never need updating.
4. Runnable Example
The following standalone example simulates chunked prefill scheduling:
# Simulates chunked prefill scheduling on a toy model.# Requires: pip install numpy
import numpy as np
CHUNK_SIZE = 4 # tokens processed per prefill chunk per iterationVOCAB = 32 # toy vocabulary sizeD_MODEL = 8 # tiny embedding dimension
class Request: """A single inference request (推理请求).""" def __init__(self, req_id: str, prompt_tokens: list[int]): self.req_id = req_id self.prompt = prompt_tokens self.processed = 0 # how many prompt tokens have been prefilled self.kv_cache: list = [] # accumulated KV pairs (simulated as ints) self.output_tokens: list[int] = [] self.is_decoding = False
def is_prefill_done(self) -> bool: return self.processed >= len(self.prompt)
def fake_attention(tokens: list[int], kv_cache: list) -> list: """Simulates attention output — returns dummy KV entries.""" return [t * 2 for t in tokens] # fake KV = token_id * 2
def fake_decode(kv_cache: list, rng: np.random.Generator) -> int: """Samples a token given the completed KV cache.""" return int(rng.integers(0, VOCAB))
def run_chunked_prefill(requests: list[Request], max_new_tokens: int = 5): rng = np.random.default_rng(42) prefill_queue = list(requests) decode_queue: list[Request] = [] iteration = 0
while prefill_queue or decode_queue: iteration += 1 print(f"\n--- Iteration {iteration} ---")
# ── Decode step (解码步骤): one token per running request ────────── for req in list(decode_queue): tok = fake_decode(req.kv_cache, rng) req.output_tokens.append(tok) print(f" [Decode] {req.req_id}: generated token {tok}") if len(req.output_tokens) >= max_new_tokens: decode_queue.remove(req) print(f" [Done] {req.req_id} finished.")
# ── Prefill chunk (预填充分块): one chunk from the head of the queue ─ if prefill_queue: req = prefill_queue[0] start = req.processed end = min(start + CHUNK_SIZE, len(req.prompt)) chunk = req.prompt[start:end] kv = fake_attention(chunk, req.kv_cache) req.kv_cache.extend(kv) req.processed = end print(f" [Prefill] {req.req_id}: tokens [{start}:{end}] → KV len={len(req.kv_cache)}")
if req.is_prefill_done(): prefill_queue.pop(0) decode_queue.append(req) print(f" [Ready] {req.req_id}: prefill complete → decode queue")
if __name__ == "__main__": reqs = [ Request("R1", list(range(10))), # 10-token prompt → needs 3 chunks Request("R2", list(range(6))), # 6-token prompt → needs 2 chunks ] run_chunked_prefill(reqs, max_new_tokens=3)Expected output (abridged):
--- Iteration 1 --- [Prefill] R1: tokens [0:4] → KV len=4
--- Iteration 2 --- [Prefill] R1: tokens [4:8] → KV len=8
--- Iteration 3 --- [Prefill] R1: tokens [8:10] → KV len=12 [Ready] R1: prefill complete → decode queue
--- Iteration 4 --- [Decode] R1: generated token 17 [Prefill] R2: tokens [0:4] → KV len=4...5. Benefits and Trade-offs (优缺点)
| Aspect | Without Chunked Prefill | With Chunked Prefill |
|---|---|---|
| TTFT (首个令牌时间) | Unpredictable, spikes on long prompts | More predictable, bounded by chunk size |
| Decode stalls (解码停顿) | Long stalls during large prefills | Eliminated — decode runs every iteration |
| GPU utilization (GPU利用率) | Suboptimal during pure decode | Higher — compute + memory-BW co-utilized |
| Implementation complexity | Simple | Moderate (state tracking per request) |
6. Key Formula — Prefill Iterations per Request
Where is the prompt length (提示长度) and is the chunk size (块大小). The request enters the decode queue after prefill iterations.
7. Related Concepts (相关概念)
- PagedAttention (分页注意力) — manages KV cache memory in pages; works naturally with chunked prefill.
- Continuous Batching (连续批处理) — iterates dynamically; chunked prefill is one scheduling strategy on top.
- Speculative Decoding (推测解码) — orthogonal technique to speed up the decode phase.
- TTFT / ITL / TBT — latency metrics affected by chunked prefill scheduling.